Esperaba que los ventiladores giraran a toda velocidad.
Acababa de pedirle a Java que iniciara 10,000 tareas, asignara a cada una su propio virtual thread, y las pusiera a todas a esperar 100 milisegundos.
En cambio, el programa terminó antes de que pudiera retirar la mano del Enter.
Lo ejecuté de nuevo. Y luego tres veces más.
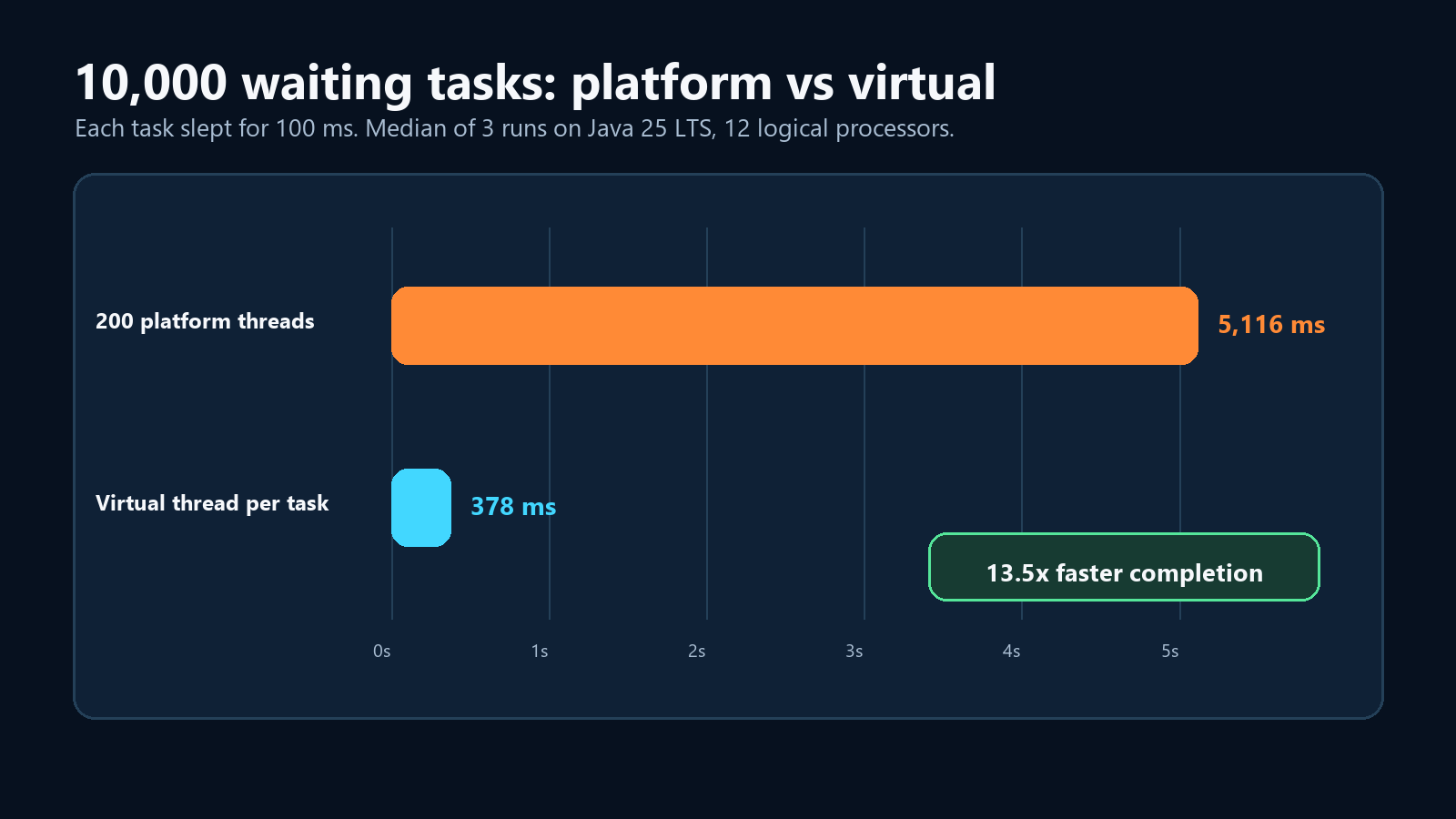
En mi laptop de 12 procesadores lógicos, la mediana de los resultados fue esta:
| Executor | 10,000 tareas en espera |
|---|---|
| Pool fijo de 200 platform threads | 5,116 ms |
| Un virtual thread por tarea | 378 ms |
Eso es 13.5x más rápido solo por cambiar el executor, no la tarea.
Esto no demuestra que los virtual threads hagan el código Java 13.5x más rápido.
Demuestra que yo había estado pensando en los threads incorrectamente.
Reconstruyamos ese modelo mental desde adentro.
Primero, Haz una Predicción
Cada tarea hace esto:
Thread.sleep(Duration.ofMillis(100));Hay 10,000 tareas.
¿Cuánto debería tardar todo el programa?
- A: Unos 1,000 segundos, porque
10,000 x 100 ms = 1,000 segundos - B: Unos 5 segundos, porque 200 platform threads procesan el trabajo en oleadas
- C: Menos de 1 segundo, porque los virtual threads en espera pueden hacerse a un lado
Las tres respuestas pueden ser correctas. El executor decide en qué mundo vives.
El Modelo Mental Antiguo
Durante la mayor parte de la vida de Java, un thread Java era un wrapper delgado alrededor de un thread del sistema operativo.
Eso hacía a los threads útiles, pero demasiado costosos como para tratarlos como un recurso ilimitado.
Si tu servidor tenía un pool de 200 platform threads y los 200 estaban esperando por una base de datos lenta, la solicitud 201 tenía que hacer fila.
solicitud -> platform thread -> OS thread -> espera
solicitud -> platform thread -> OS thread -> espera
solicitud -> cola -> -> esperar por un thread libreEl código estaba bloqueado, pero el thread del sistema operativo asignado seguía ocupado.
Los virtual threads rompen esa relación uno a uno.
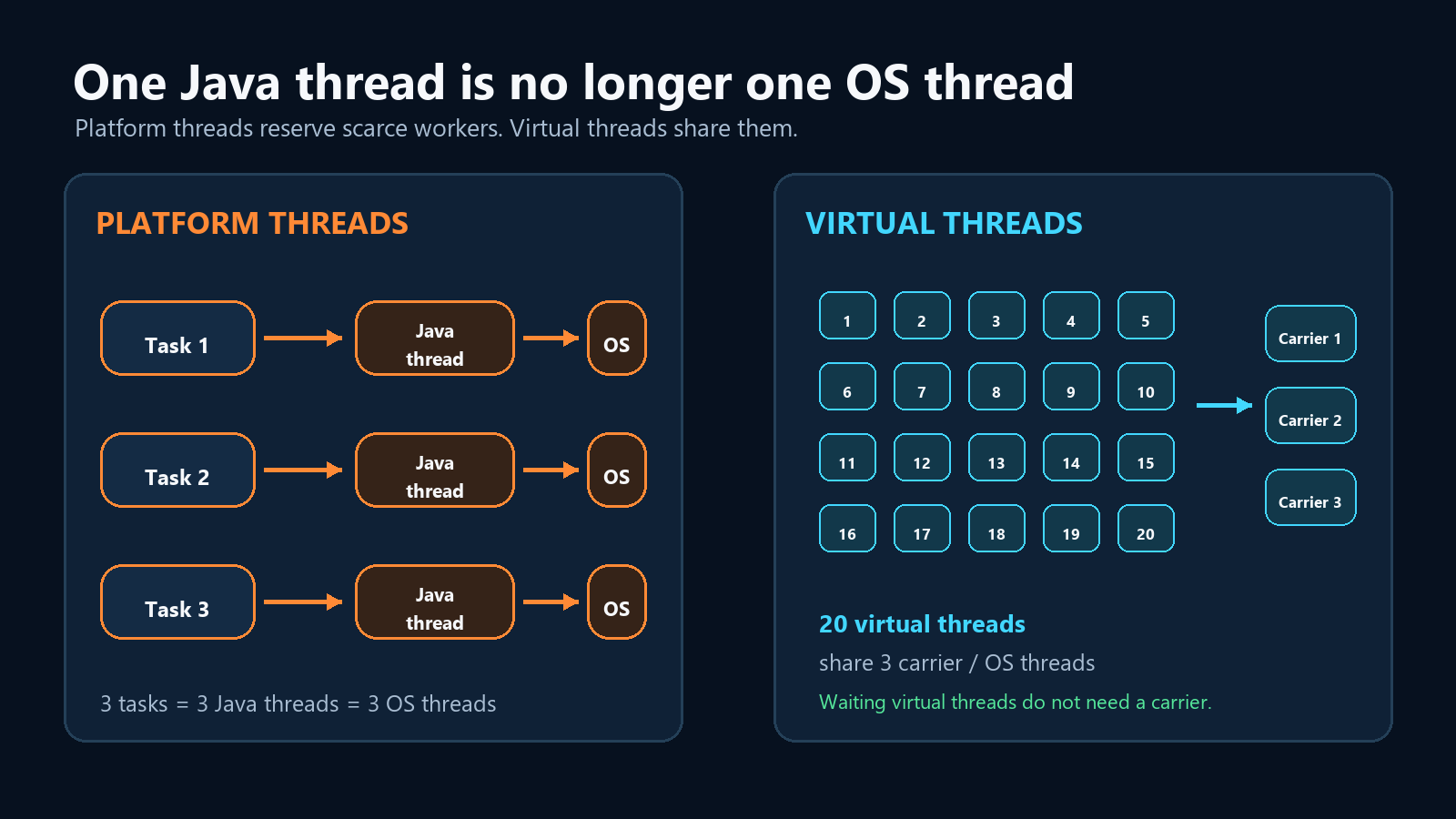
Un virtual thread sigue siendo un java.lang.Thread real.
La diferencia es que no posee permanentemente un thread del SO. La JVM programa muchos virtual threads sobre un número menor de platform threads, llamados carrier threads.
Puedes ver la diferencia directamente:
Thread platform = Thread.ofPlatform().start(
() -> System.out.println(Thread.currentThread().isVirtual())
);
Thread virtual = Thread.ofVirtual().start(
() -> System.out.println(Thread.currentThread().isVirtual())
);
platform.join();
virtual.join();Salida:
false
trueMisma API Thread. Modelo de scheduling diferente.
¿Qué Pasa Cuando un Virtual Thread Espera?
Imagina un virtual thread ejecutándose en el carrier thread 3.
Llama a una operación de bloqueo soportada, como Thread.sleep() o I/O de red bloqueante.
La JVM puede:
- Pausar el virtual thread.
- Desmontarlo del carrier thread 3.
- Usar el carrier thread 3 para ejecutar otros virtual threads.
- Remontar el virtual thread original cuando termine su espera.
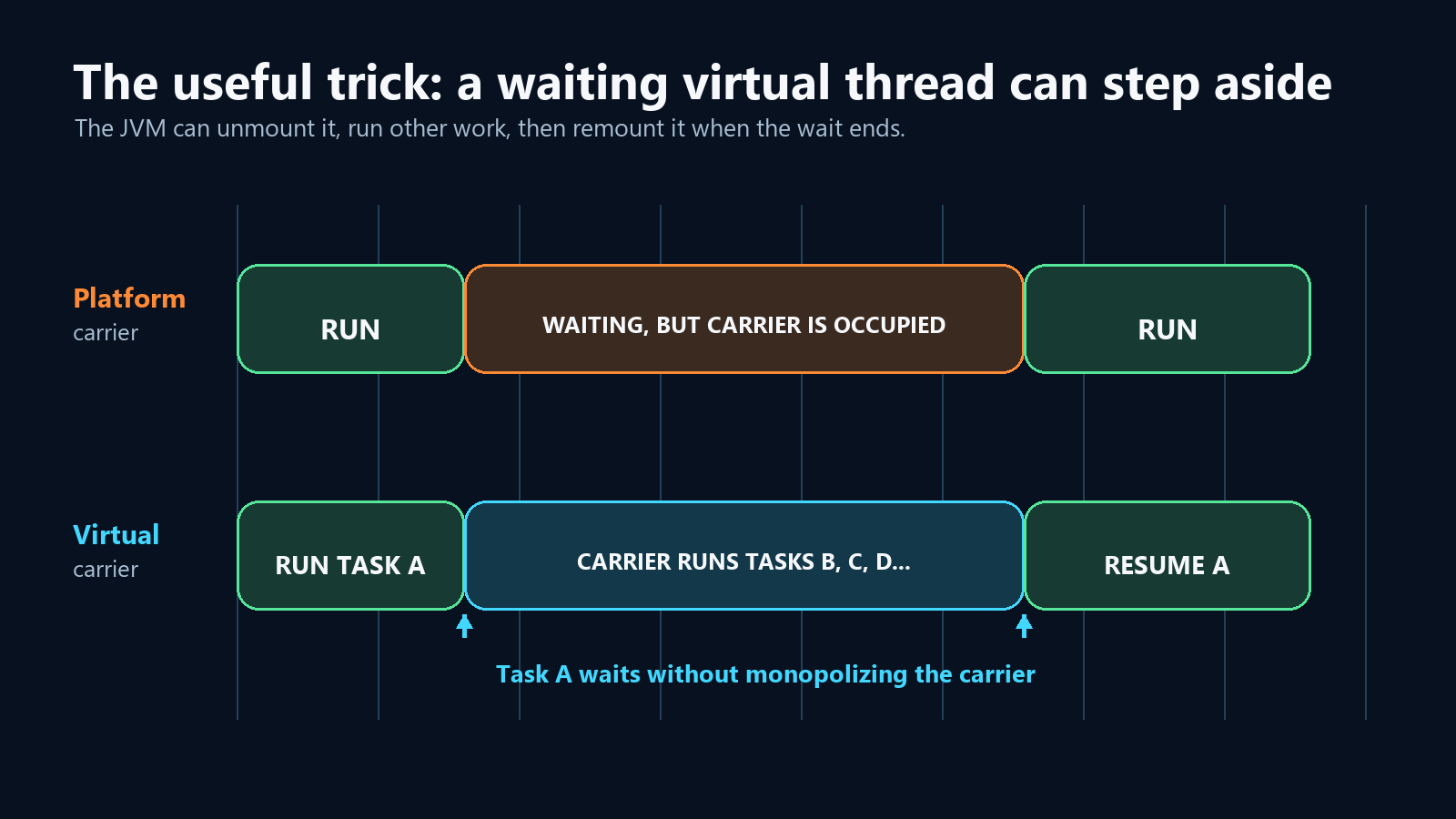
El virtual thread no hizo que la base de datos, la red o el temporizador fueran más rápidos.
Dejó de desperdiciar un carrier thread escaso mientras esperaba.
Esa frase es toda la funcionalidad:
Los virtual threads hacen que esperar sea barato. No hacen que el trabajo sea barato.
El Experimento
Esta es la parte importante del benchmark:
private static final int TASKS = 10_000;
private static final Duration WAIT = Duration.ofMillis(100);
private static void run(ExecutorService executor) throws Exception {
try (executor) {
List<Future<Integer>> futures = new ArrayList<>(TASKS);
for (int task = 0; task < TASKS; task++) {
int taskId = task;
futures.add(executor.submit(() -> {
Thread.sleep(WAIT);
return taskId;
}));
}
for (Future<Integer> future : futures) {
future.get();
}
}
}Ejecuté el mismo método con dos executors:
run(Executors.newFixedThreadPool(200));
run(Executors.newVirtualThreadPerTaskExecutor());El primer executor permite que máximo 200 tareas esperen a la vez.
El executor de virtual threads inicia un virtual thread por cada tarea. Cuando las tareas duermen, la JVM puede desmontarlas y mantener sus carrier threads disponibles.
Por eso el pool fijo se comporta aproximadamente así:
10,000 tareas / 200 threads = 50 oleadas
50 oleadas x 100 ms = unos 5 segundosLa versión con virtual threads no necesita 50 oleadas. Casi todas las tareas pueden comenzar, dormir, y salirse del camino de los carriers.
Las medianas medidas de tres ejecuciones fueron:
TRABAJO EN ESPERA
200 platform threads 5,116 ms
virtual thread por tarea 378 ms
TRABAJO CPU
platform threads 2,387 ms
virtual threads 2,300 msEl resultado de espera cambió drásticamente.
El resultado de CPU no.
La Trampa del Benchmark
Los virtual threads no son pequeños botones turbo.
Para probar eso, también envié 48 tareas intensivas en CPU que contaban primos hasta 1,000,000.
Ambos executors terminaron en aproximadamente el mismo tiempo porque mi laptop seguía teniendo solo 12 procesadores lógicos.
Puedes crear un millón de virtual threads.
No puedes crear un millón de núcleos de CPU.
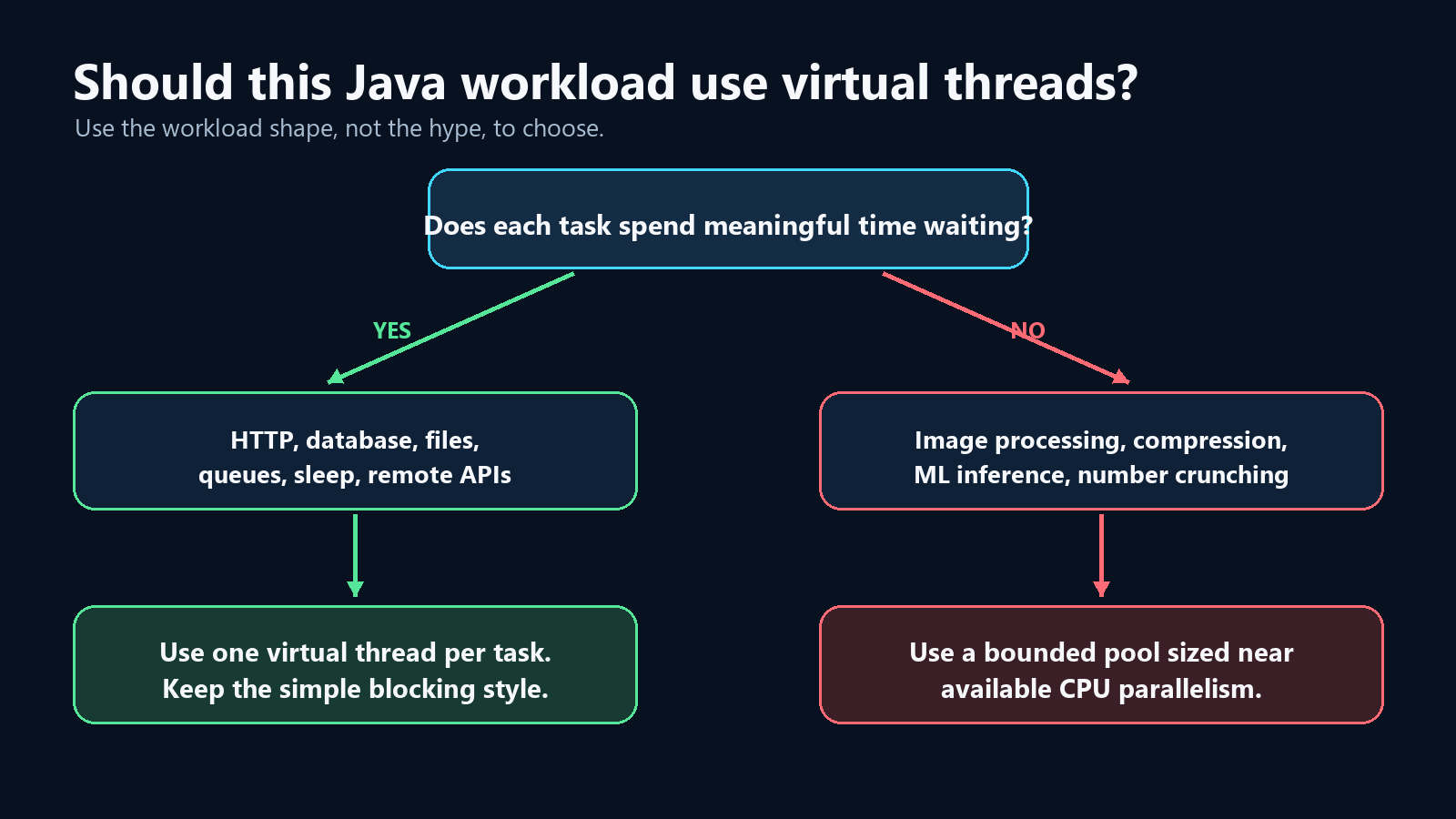
Buenos candidatos para virtual threads son workloads que pasan tiempo significativo esperando:
- Peticiones HTTP
- Consultas a bases de datos
- Operaciones de archivo (después de perfilado)
- Colas de mensajes
- Llamadas a APIs remotas
- Múltiples
sleep()o temporizadores independientes
Malos candidatos son los que pasan la mayor parte del tiempo calculando:
- Procesamiento de imágenes
- Codificación de video
- Compresión
- Inferencia de machine learning
- Transformaciones grandes en memoria
- Cálculo numérico intensivo
Para trabajo bound a CPU, usa paralelismo acotado cercano a la cantidad de CPU que tu máquina puede ejecutar realmente.
La Regla Más Simple y Útil
Cuando las tareas principalmente esperan:
try (var executor = Executors.newVirtualThreadPerTaskExecutor()) {
Future<String> user = executor.submit(() -> loadUser());
Future<List<Order>> orders = executor.submit(() -> loadOrders());
renderProfile(user.get(), orders.get());
}Este código es ordinario, bloqueante y legible.
Eso es intencional.
Por años, los desarrolladores a menudo tenían que elegir entre código simple thread-por-solicitud que no escalaba, y código asíncrono que escalaba pero fragmentaba el flujo de trabajo entre callbacks, futures u operadores reactivos.
Los virtual threads hacen que la forma simple sea práctica para muchas aplicaciones bloqueantes de alto throughput.
No eliminan todos los problemas de concurrencia. Eliminan una suposición costosa: que cada tarea concurrente necesita su propio thread del SO.
No Hagas Pool de Virtual Threads
Esto se siente mal al principio.
Aprendimos a hacer pool de threads porque los platform threads eran costosos. Un pool limitaba cuántos de esos threads escasos existían.
Los virtual threads están diseñados para crearse por tarea.
Así que este es el patrón normal:
Executors.newVirtualThreadPerTaskExecutor();No esto:
un pequeño pool de virtual threads reutilizablesSi debes limitar el acceso a algo escaso, limita esa cosa.
Supón que una API de socio permite solo 20 solicitudes concurrentes:
Semaphore partnerApiSlots = new Semaphore(20);
String callPartnerApi() throws InterruptedException {
partnerApiSlots.acquire();
try {
return makeBlockingHttpRequest();
} finally {
partnerApiSlots.release();
}
}
El executor aún puede crear un virtual thread por tarea.
El semáforo protege el cuello de botella real.
Esta separación es útil mucho más allá de los virtual threads:
Concurrencia es cuánto trabajo puede estar en progreso. Capacidad es cuánto trabajo puede aceptar una dependencia de forma segura.
La Trampa Silenciosa de ThreadLocal
Los virtual threads soportan ThreadLocal, así que el contexto de solicitud como un ID de usuario o trace ID puede seguir funcionando.
El patrón peligroso es usar ThreadLocal como un pequeño pool de objetos:
private static final ThreadLocal<ExpensiveClient> CLIENT =
ThreadLocal.withInitial(ExpensiveClient::new);Eso puede parecer eficiente cuando 200 platform threads en pool reutilizan 200 clientes.
Con un virtual thread por tarea, puede convertirse silenciosamente en miles de clientes costosos que apenas se reutilizan.
Mantén el contexto en variables thread-local solo cuando realmente pertenezca a la tarea. No las uses para cachear objetos pesados reutilizables por virtual thread.
Puedes Observarlos
Los virtual threads son invisibles para el sistema operativo porque el SO ve los carrier threads, no cada virtual thread.
El JDK los entiende, sin embargo.
Puedes crear un dump consciente de virtual threads con:
jcmd <pid> Thread.dump_to_file -format=json threads.jsonEsa distinción importa durante la depuración. Un dashboard del SO puede mostrar un número modesto de threads mientras la JVM gestiona miles de virtual threads.
La pregunta correcta no es solo “¿cuántos threads existen?”
Es “¿qué están esperando esos threads?”
Una Advertencia Desactualizada
Puede que hayas leído este consejo:
Nunca bloquees dentro de código
synchronizedcuando uses virtual threads, porque fija el carrier thread.
Esa advertencia importaba cuando los virtual threads se volvieron definitivos en Java 21.
Java 24 cambió la implementación mediante JEP 491. Los virtual threads ahora pueden liberar su carrier cuando bloquean dentro de código synchronized en el caso normal.
El pinning no ha desaparecido por completo. Las llamadas nativas y de foreign function aún pueden fijar un virtual thread.
Pero la regla absoluta de “virtual threads y synchronized no se mezclan” está desactualizada en JDKs modernos.
Esta es una razón por la que ejecuté el experimento en Java 25 LTS en lugar de repetir una lista de verificación anticuada de Java 21.
Checklist de Migración en Cinco Minutos
No reescribas una aplicación porque los virtual threads suenen emocionantes.
Toma un flujo de trabajo bloqueante e inspecciónalo.
- Confirma que el workload espera. Busca llamadas a BD, HTTP, acceso a archivos, colas y sleeps.
- Reemplaza el executor de tareas. Prueba
Executors.newVirtualThreadPerTaskExecutor(). - Mantén los límites downstream. Los pool de conexiones, cuotas de API y rate limits siguen existiendo.
- Haz load test del camino real. Un benchmark con sleep enseña el modelo, no tu capacidad en producción.
- Mide CPU y memoria también. Threads baratos aún pueden ejecutar código costoso o retener objetos grandes.
- Revisa las integraciones nativas. Las llamadas nativas son uno de los casos de pinning restantes.
El objetivo no es “usa virtual threads en todas partes”.
El objetivo es “deja de pagar por threads del SO ociosos donde no los necesitas”.